DES303 Week 6: User Testing, Trust Problems, and Reframing Focus Integrity
Introduction
Week 6 was the point where Tickers moved from being a prototype I was building into a system that real users and peers could react to. In Week 5, I had already developed the arena flow, to-do system, Pomodoro/session record, Django backend, Chrome lock logic, and the first version of the Focus Integrity layer. In Week 6, I tested these parts with users and brought the prototype into critique.
The Week 6 task asks us to reflect on our first round of experiments, respond to feedback from the critique, plan a second round of experimentation, and keep documenting the making process. The most important learning this week did not come from a polished final screen. It came from what broke, what users questioned, and what the critique revealed.
The main feedback was not only about interface design. Users and peers questioned whether the system could actually be trusted. Some problems were engineering issues, such as Pomodoro time records not always working and backend failures happening too often. I mostly fixed those, and users became more satisfied once the system behaved more reliably. However, other feedback raised deeper design questions: whether the Focus Integrity score was fair, whether money stakes actually improved focus, whether users would accept Chrome/app locking, whether the app only works among friend groups, and whether privacy itself could become a type of wager.
This changed the direction of my project. I realised that Tickers is not just a productivity game. It is a social trust system. The arena can make productivity more motivating, but only if the timer, backend, Chrome lock, and Focus Integrity judgement feel reliable, explainable, and fair.
Experience
Testing the arena, to-do, and Pomodoro flow
This week I tested the arena, to-do, and Pomodoro flow across multiple users. This was not a formal user study yet. It was still prototype testing, but it was much closer to real use than static wireframes. Users could create or select tasks, enter the arena, start Pomodoro-style sessions, and experience the basic loop of committing to work in a shared space.
This was encouraging because it showed that the social commitment idea was readable. Users understood that Tickers was not just a timer. The arena made the task feel more serious because the work was connected to other people and to a shared outcome. However, testing also revealed several problems. The strongest feedback was about reliability and trust.
| User feedback | Type of issue | What I did or learnt |
|---|---|---|
| Focus Integrity score felt inconsistent or wrong | Judgement trust issue | I need to compare scoring models instead of relying on one score. |
| Pomodoro / arena time record sometimes failed | Engineering reliability issue | I mostly fixed the session timing and record logic. |
| Backend failure happened too often | Engineering reliability issue | I mostly fixed backend stability and sync issues. |
| Users were more satisfied after reliability fixes | Prototype validation | Some problems were engineering blockers, not concept failures. |
| Arena made most sense among friends | Social design issue | Tickers works best first as a friend-group nudging system. |
This helped me separate engineering failures from design research problems. Timer and backend failures were things I needed to fix because they blocked the experience. Once I mostly fixed them, users became more satisfied, and the deeper design questions became clearer. The remaining problem was not only whether the app worked. It was whether users would trust the system's judgement.
Week 6 critique feedback
The critique added another layer of feedback. The comments were not mainly about whether the interface looked good. They were about whether Tickers could work socially, ethically, and technically.
| Crit feedback | My response or reflection | What it revealed |
|---|---|---|
| What if the Focus Integrity score is wrong? | Compare models and show confidence, not truth. | The score needs to be explainable and contestable. |
| What if the user deletes the app? | The arena commitment still exists socially. | Tickers relies on social enforcement, not only technical enforcement. |
| How does Chrome lock get detected? | Users choose blocked apps/sites and can label ambiguous tabs. | Blocking needs to be user-controlled and explainable. |
| What if users do not want to bet money? | Money works best as a playful friend-group stake at this stage. | Stakes need to match the social context. |
| Does betting money actually improve efficiency? | Early experience suggests seriousness, but I do not have statistics yet. | Motivation needs to be tested, not assumed. |
| Does this only work if all friends use it? | Nearby friend groups are the right first context. | Tickers depends on social adoption and real relationships. |
| What if the stake is privacy instead of money? | This became one of the strongest speculative ideas. | Privacy could become the wager, not only money. |
| What is the future direction? | Hardware may come later. | Hardware only makes sense after the software trust layer improves. |
One critique asked what happens if a user simply deletes the app during an arena session. My answer was that deleting the app does not automatically remove the user from the arena commitment. If the user has already entered a room and agreed to a stake, the commitment still exists socially. Their friends can still hold them accountable because the arena is not only technical enforcement. It is also a social contract.
However, this also showed a weakness. Relying on friends to enforce a stake can become socially messy. It could create pressure, conflict, or awkwardness. In a later version, deleting the app, disconnecting the tracker, or leaving mid-session should probably mark the session as abandoned, unverified, or stake unresolved, rather than simply disappearing.
Another critique asked how Chrome lock or browser activity is detected. My response was that users can choose which apps or websites to block during study. For new tabs or ambiguous browsing, the user can decide whether the activity is for work or not. This gives the system a way to learn the user's task context instead of blindly treating all browsing as distraction.
Timer records and backend sync must behave reliably.
Focus Integrity needs confidence, evidence, and challenge paths.
Chrome lock and abandoned sessions must be visible and fair.
Money, reputation, and privacy stakes change the ethical weight.
The arena is most believable among real friend groups first.
Evidence should be controlled, temporary, and minimally exposed.
Reflection on Action
Before Week 6, I saw many of the prototype problems as technical problems. If the Pomodoro record failed, I treated it as a timer bug. If the backend failed, I treated it as a sync issue. If the Focus Integrity score was wrong, I treated it as an algorithm problem.
After user testing and critique, I realised that these are also design problems because they affect trust. If the timer fails, the arena result becomes unfair. If the backend fails, the shared room state collapses. If the Focus Integrity score feels wrong, users reject the system's authority. If Chrome lock feels hidden, users feel controlled. If money is involved, users need to believe the result is fair. If privacy is at stake, the system needs to be careful about what evidence is shown.
Trust has to come before pressure.
The arena can make people take work more seriously, especially when friends are involved. However, stronger pressure is only fair if the system behind it is reliable and explainable. This means my next step should not be adding more arena features. The next step should be making Focus Integrity more trustworthy.
I also noticed my own bias as a builder. My instinct is to solve feedback by adding more logic, more signals, and more backend structure. That is useful when the problem is clearly technical, such as backend failures or broken timer records. But more tracking does not automatically make the system better. More tracking can also make the system more invasive.
How can I make the score more accurate?
What kind of evidence are users willing to accept, and how should the system explain uncertainty?
This changed how I understood Tickers. I am no longer only building a gamified productivity app. I am designing a system where focus becomes recorded, judged, challenged, and socially negotiated. That makes fairness, privacy, and trust central to the project.
What I Changed After Feedback
Engineering fixes
Some feedback was about clear engineering failures. The Pomodoro / arena time record and backend failure issues were not speculative design questions. They were broken parts of the prototype that needed to be fixed.
After fixing most of these, users were more satisfied because the system behaved more reliably. This helped me separate engineering blockers from deeper design questions. The engineering fixes improved the basic system trust, but they did not fully solve the Focus Integrity problem. The score still needed to become more consistent, explainable, and ethically acceptable.
In other words, fixing the backend and timer made the prototype usable enough to reveal the harder problem: whether users would accept the system's judgement.
| Area | Before feedback | After response | What it changed |
|---|---|---|---|
| Pomodoro / arena timer | Session time sometimes failed to record. | Mostly fixed timing and session record logic. | Engineering blocker reduced. |
| Backend sync | Room and session state could fail too often. | Mostly fixed backend stability and sync issues. | System trust improved. |
| Focus Integrity score | Score still felt inconsistent after reliability fixes. | Started model comparison dashboard. | Design research question remains. |
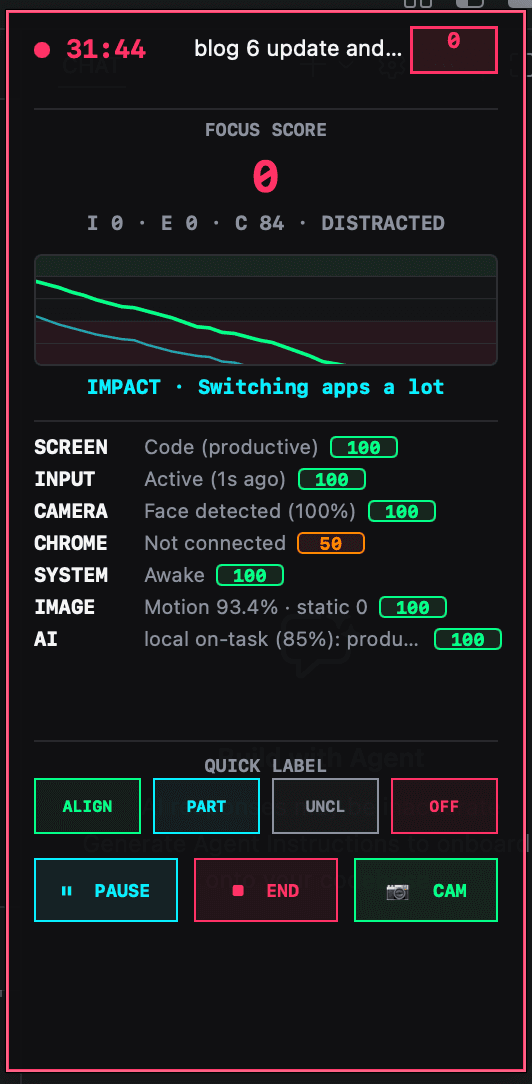
Focus Integrity comparison dashboard
In response to feedback that the Focus Integrity score felt inconsistent or wrong, I started building a score-check dashboard. The goal of this dashboard is not to prove that one algorithm is perfect. The goal is to compare different evidence approaches and see which one gives the best balance between confidence, fairness, privacy, user trust, and practical use.
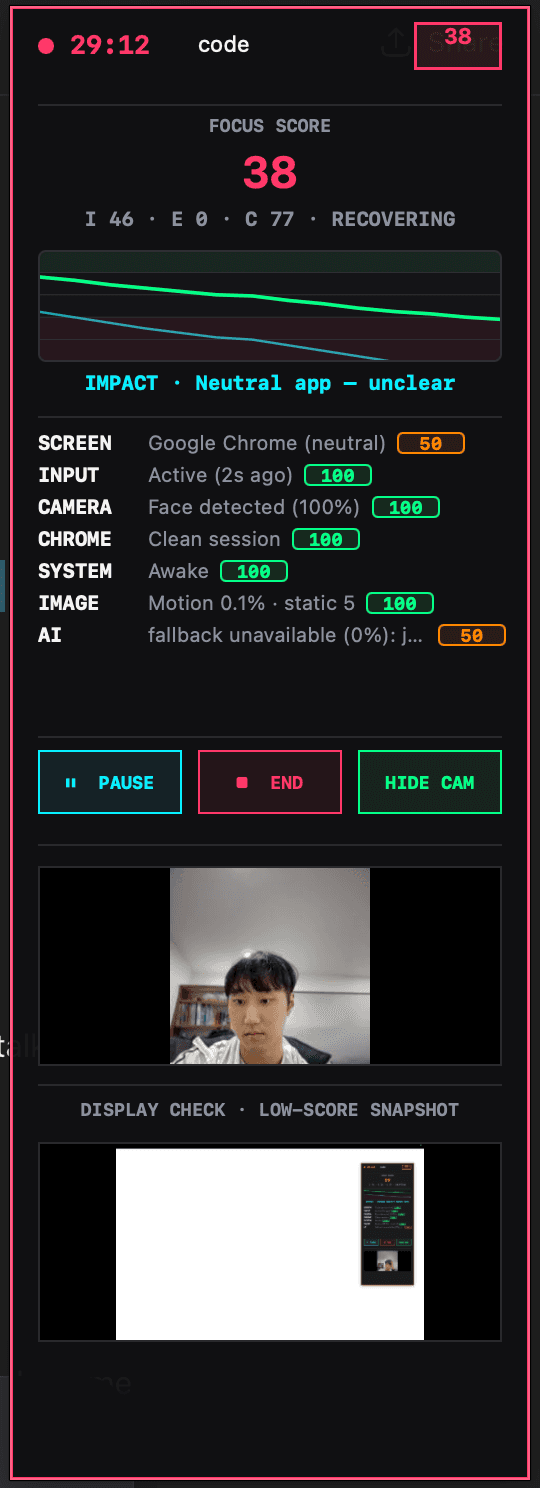
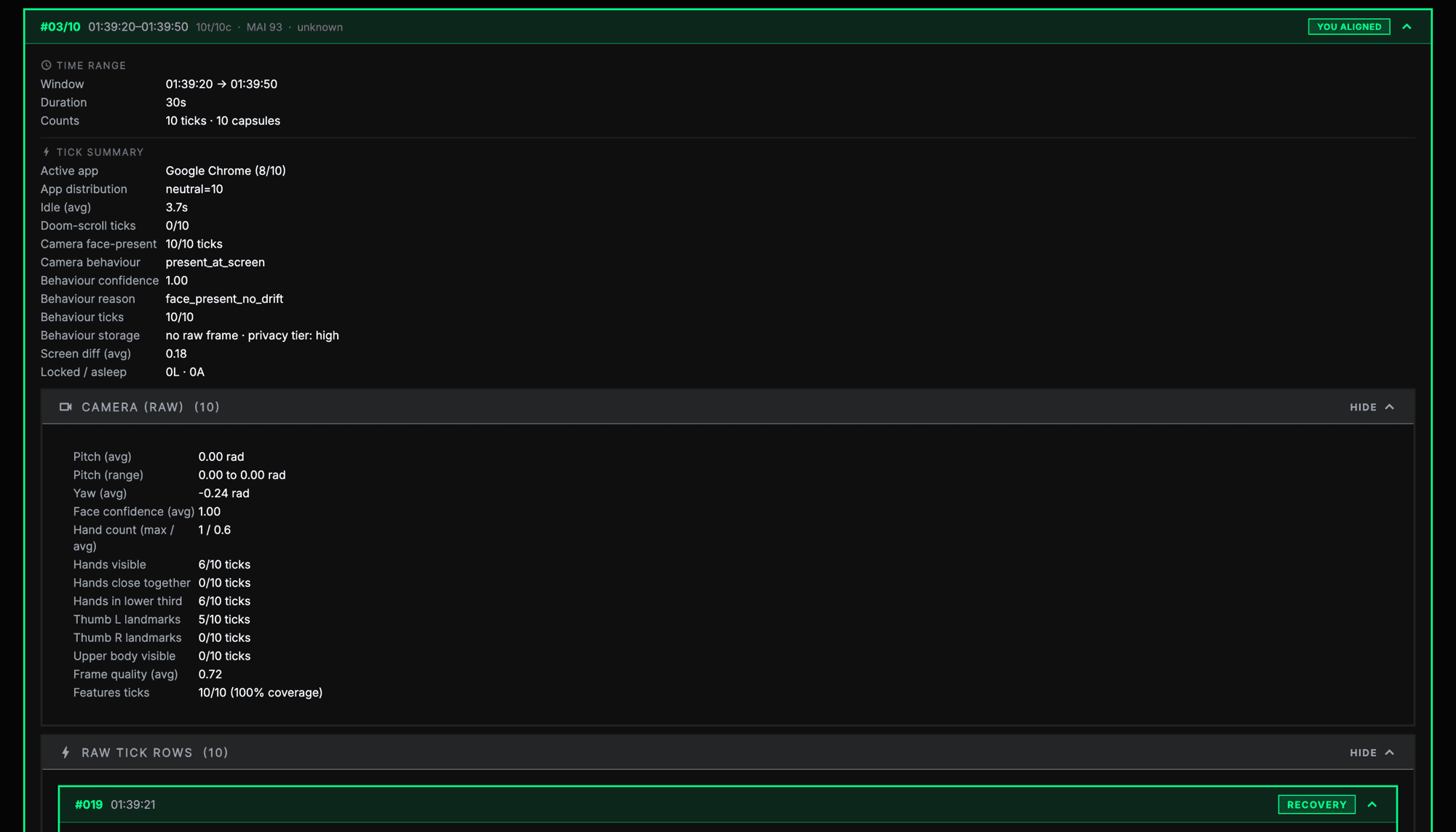
In one replayed session, the system recorded 92 ticks across about 273 seconds, with Code, Google Chrome, and Tickers appearing as active apps. The session data also included focus states such as focused, drift risk, distracted, and recovery. The validation showed a clean timeline, with monotonic timestamps, no duplicate ticks, no old ticks mixed in, and no multiple subscriptions attempted.
This matters because I can now test Focus Integrity on cleaner session data instead of judging from one unstable live score. It also lets me compare the same session across different models. The best model may not be the one that collects the most evidence. It may be the one that gives enough confidence while still feeling fair and acceptable.
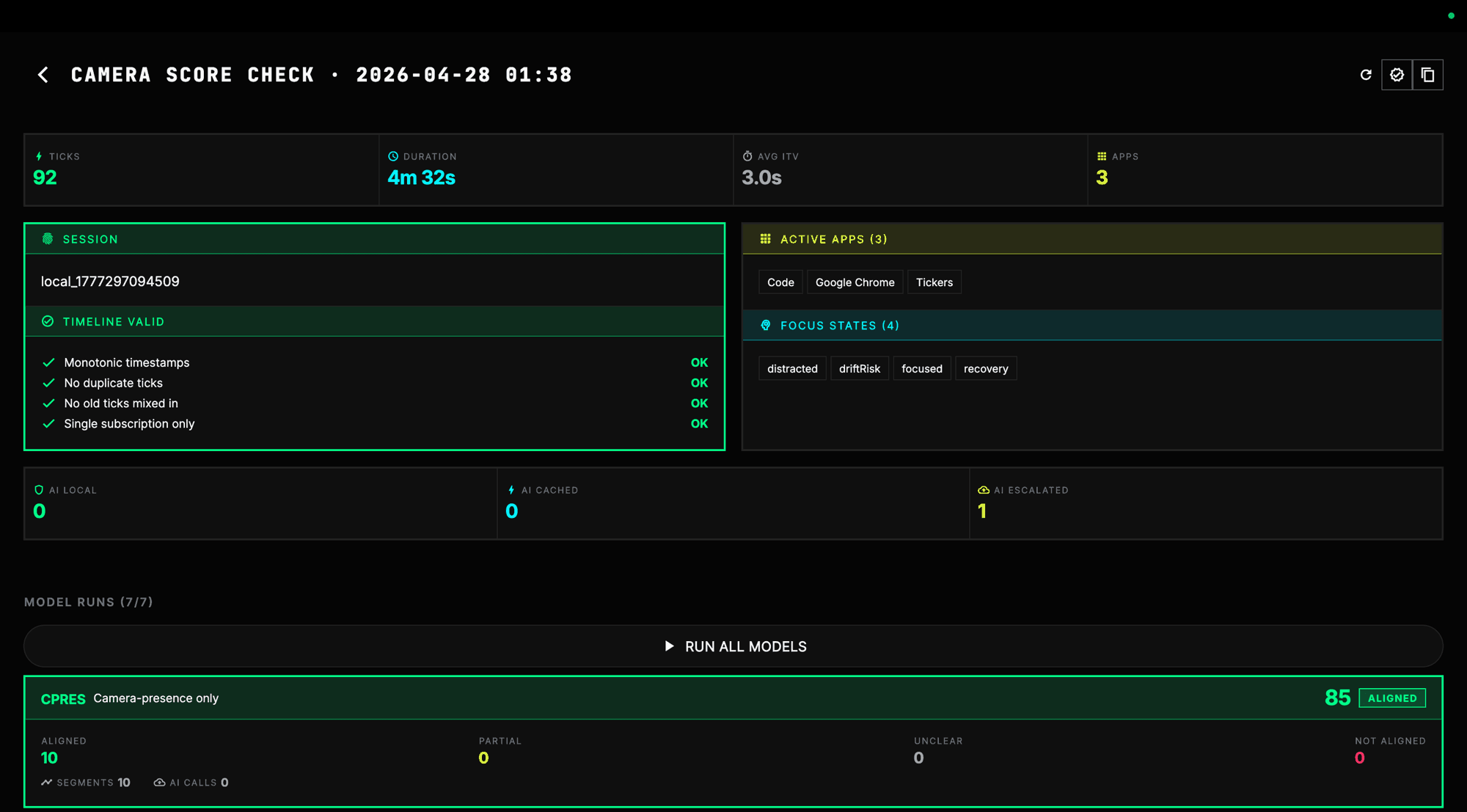
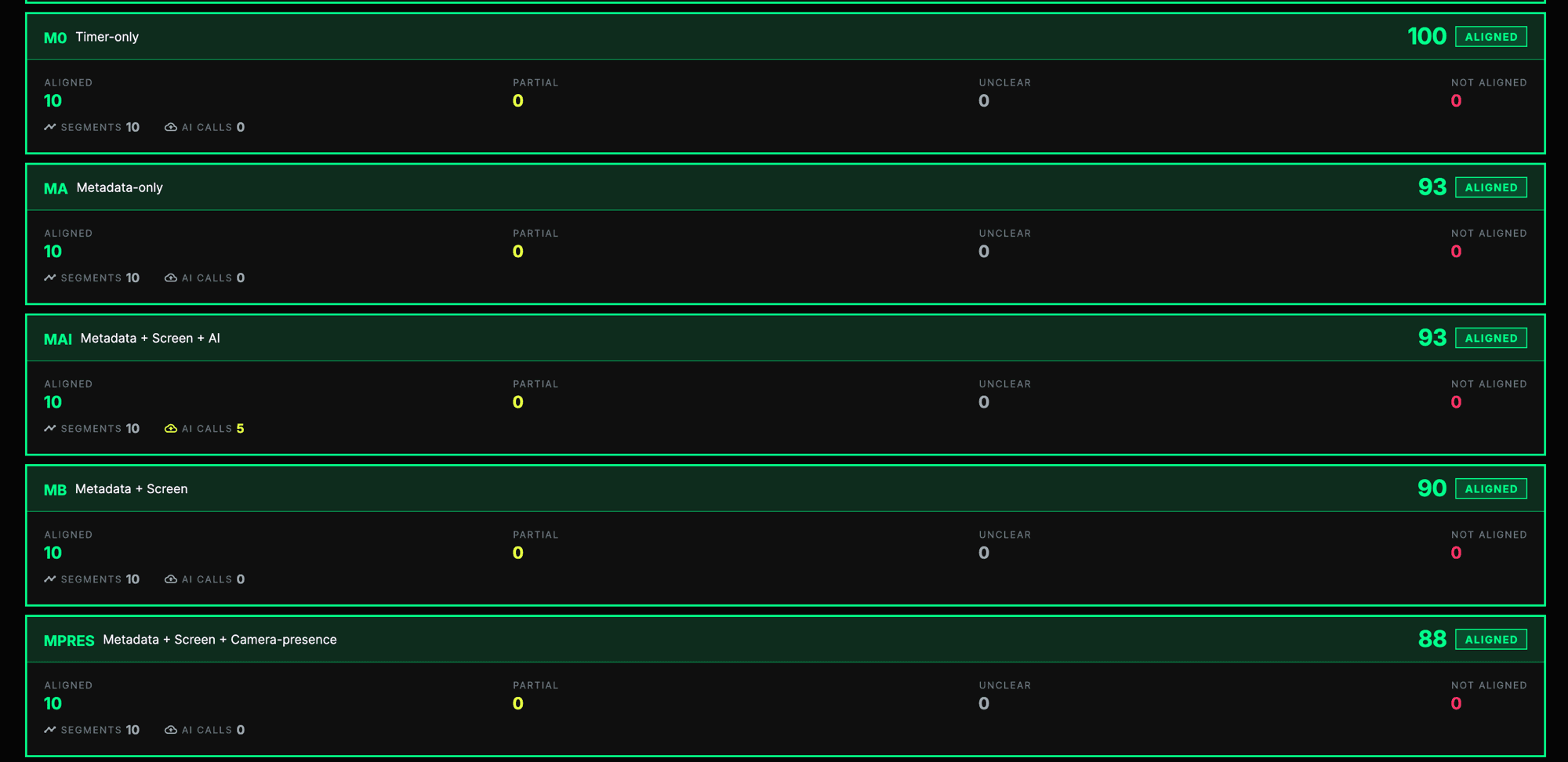
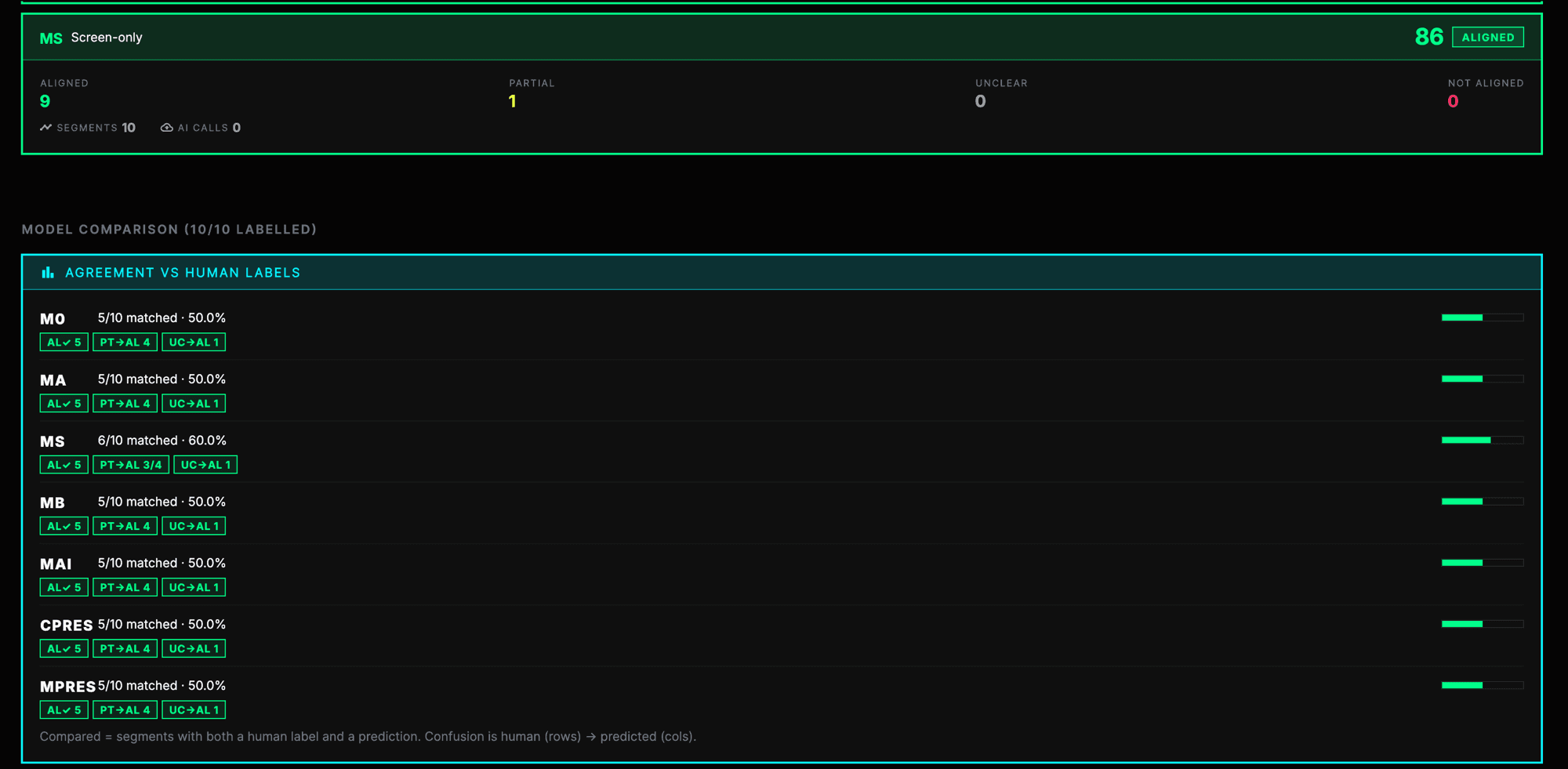
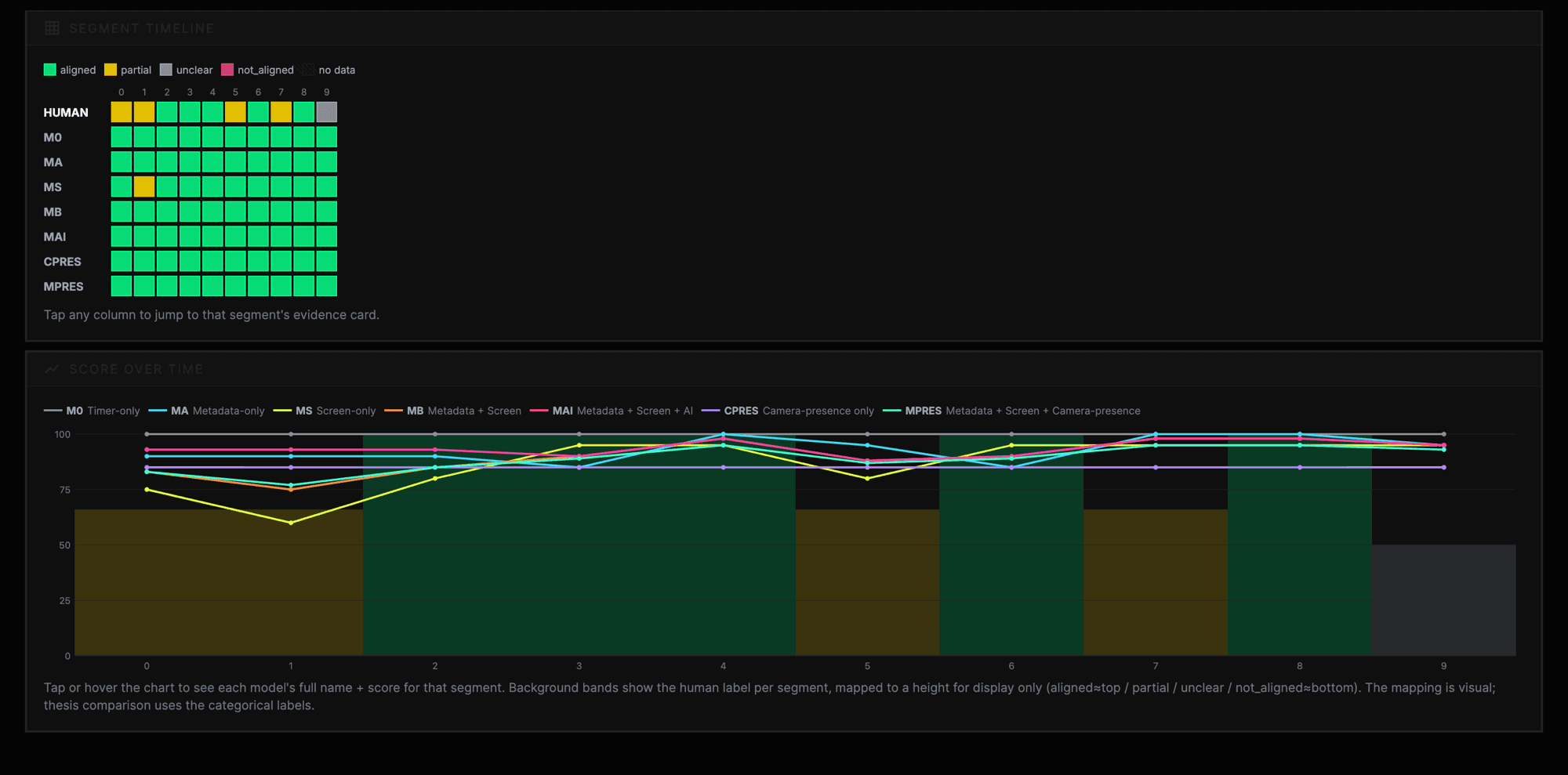
| Model | Evidence used | Why it matters |
|---|---|---|
| M0 | Timer-only | Most private, but weakest evidence. |
| MA | Metadata-only | Uses app, website, input, and activity signals. |
| MS | Screen-only | Stronger task evidence, but more privacy risk. |
| MB | Metadata + screen | A more balanced evidence approach. |
| MAI | Metadata + screen + AI | Tests whether AI improves judgement. |
| CPRES | Camera-presence only | Tests presence without screen evidence. |
| MPRES | Metadata + screen + camera-presence | Stronger evidence, but more invasive. |


Shows work context but can misread intention.
Good for activity, weak for reading or planning.
Can detect leaving, but may feel proctoring-like.
Helps detect movement without reading all content.
Useful for abandoned or unverifiable sessions.
Needs explanation because it is not truth.
Theory
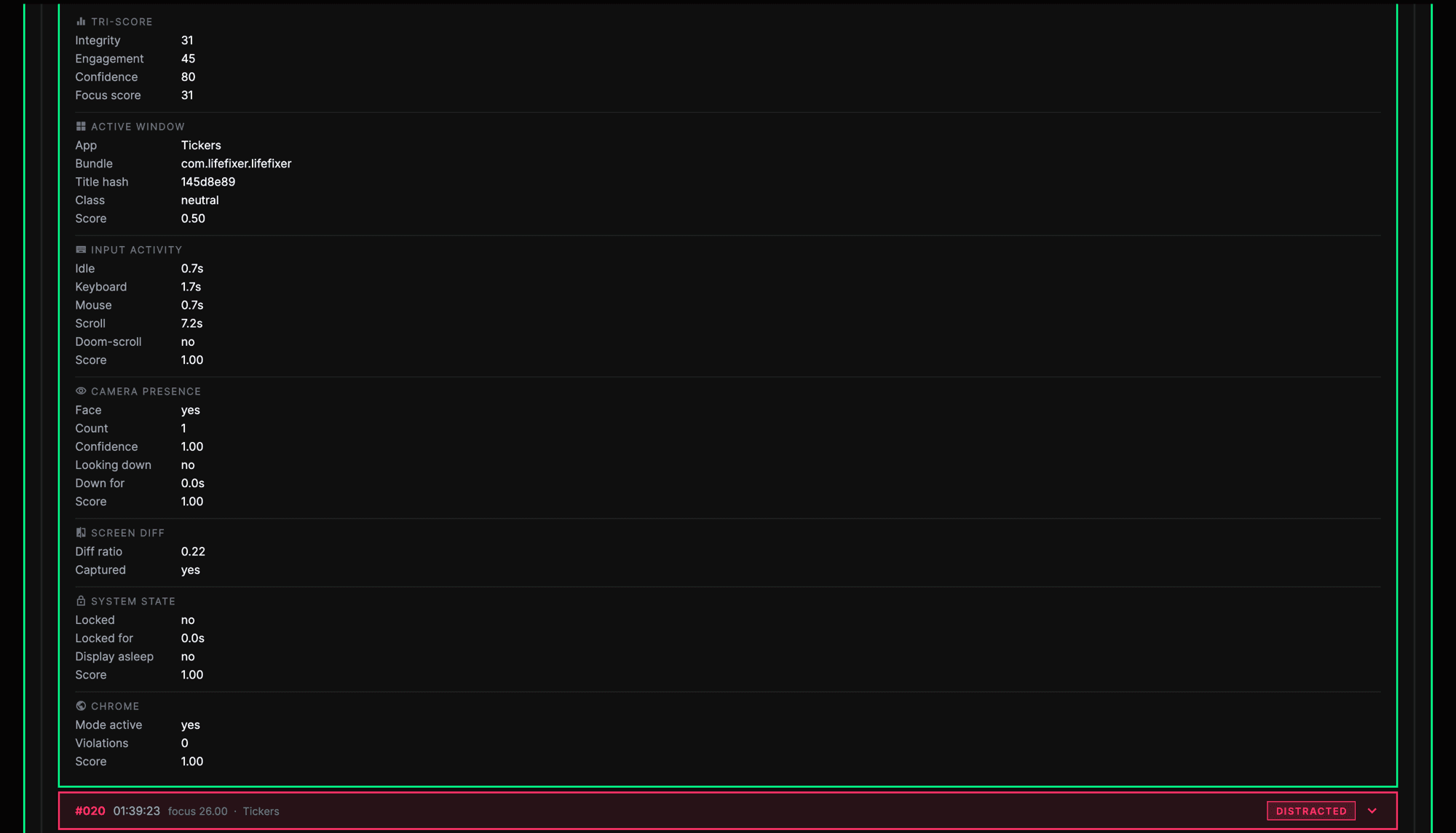
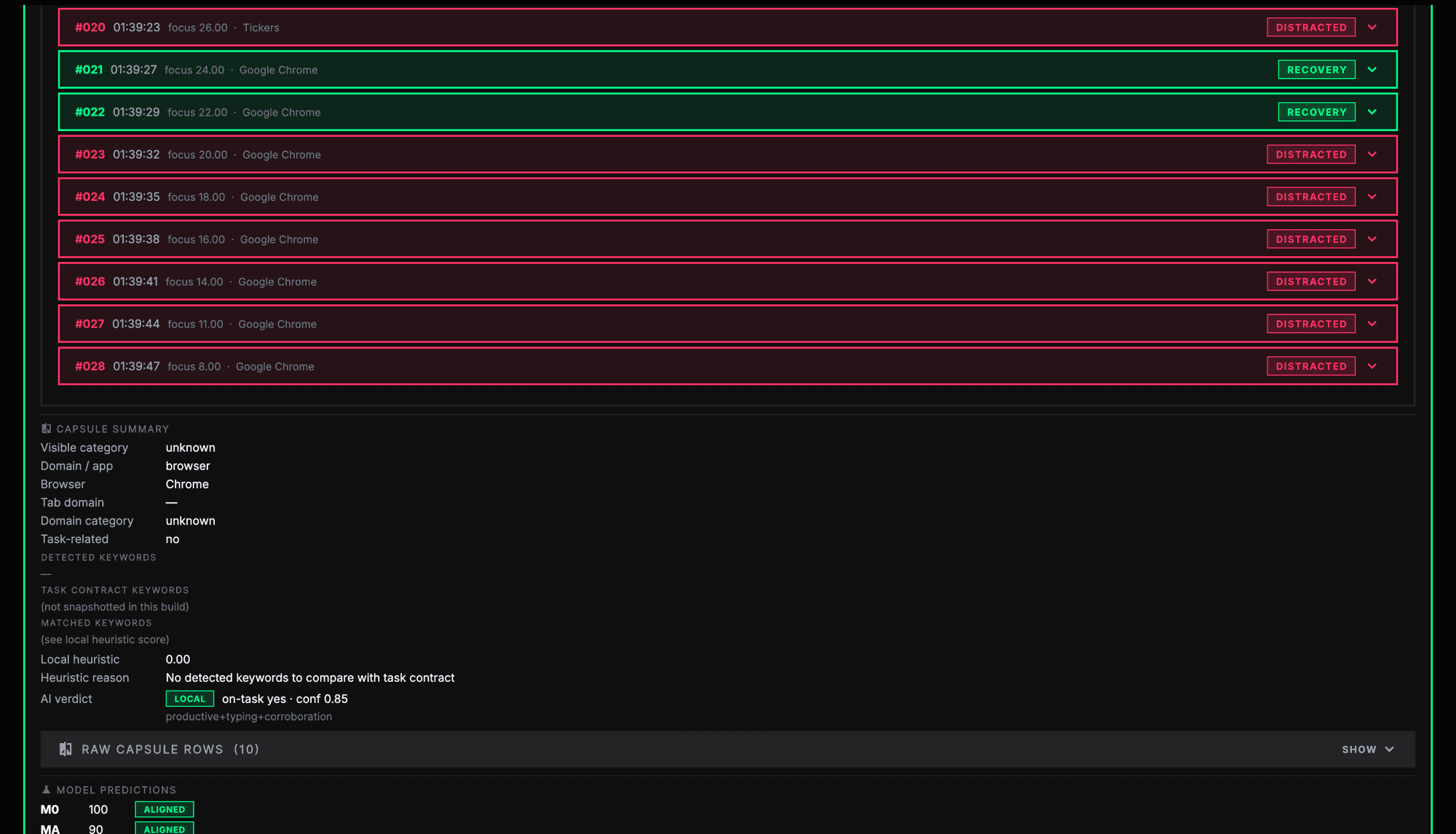
This week helped me define Focus Integrity more carefully. Focus Integrity should not be treated as a truth score. It should be a confidence-based estimate of whether the user's observable behaviour matches their selected task. Focus Integrity is not a direct measurement of attention, effort, productivity, intelligence, or character. It is an estimate of whether available evidence is consistent with the selected task.
This distinction matters because the system does not truly know the user's intention. It reads signals such as timer state, active app, browser activity, screen changes, input activity, camera presence, and task context. These signals can help, but they are still indirect. A user could be genuinely working while reading, thinking, planning, or writing handwritten notes. Another user could have a relevant app open while mentally distracted.
This also explains why adding more signals is not automatically the best answer. My research framing treats monitoring intensity as a design variable rather than an automatic improvement. Metadata may be more private but weaker for ambiguous tasks. Screen-based analysis may improve task evidence but risks exposing visible content. Presence-based checking may help identify whether the user is physically present, but it can feel proctoring-like and does not prove attention. Proof-of-work and post-session clarification may improve fairness, but they add user effort.
Which model gives enough confidence while remaining fair, explainable, private, and acceptable to users?
This links directly back to the Week 6 critique. Users and peers were not only asking whether the system worked. They were asking whether the system had the right to judge them. That is why Focus Integrity needs to be designed as a confidence-based, contestable layer, not a black-box authority.
Privacy as a Possible Stake
One of the strongest critique ideas was that the stake does not have to be money. It could be privacy.
At first, this sounded extreme, but I think it is a strong speculative idea. If Tickers uses screen evidence, camera presence, app activity, or task records, then privacy is already part of the system. Usually that privacy cost is hidden in the background as “data collection”. By turning privacy into a visible stake, the project can ask a clearer question:
Would people risk personal evidence in order to be trusted?
I do not want to implement this literally as raw camera footage or raw screen exposure. That would be too risky and could become harmful. But it could be tested safely through controlled evidence formats, such as blurred evidence cards, limited proof summaries, confidence timelines, temporary proof visibility, and failed-session evidence summaries.
This makes the project less about gambling and more about the cost of being verified.
Chrome Lock and Task-Based Blocking
Another critique question was about how Chrome lock or website blocking gets detected. My current answer is that users can choose which apps or sites to block during study. For new tabs or ambiguous browsing, the user can decide whether the activity is for work or not. This gives the system a way to learn task context instead of treating all browsing as distraction.
Later, blocked apps and sites could be separated by study type. YouTube may be distracting during coding, but valid during lecture study. Google Chrome may be distracting during writing, but necessary during research. This means the blocking system should not use one fixed rule for every session. It should adapt to the type of study the user declares.
| Study type | Possible allowed activity | Possible blocked activity |
|---|---|---|
| Coding | Visual Studio Code, GitHub, documentation, Stack Overflow | TikTok, unrelated YouTube, social media |
| Writing | Google Docs, academic databases, reference manager | Gaming sites, unrelated videos |
| Lecture watching | YouTube lecture, university LMS, note-taking app | Entertainment videos, messaging apps |
| Research | Google Chrome, PDFs, library search, Zotero | Social feeds, shopping, unrelated browsing |
Money, Friends, and Nudging
A major critique question was whether betting money actually helps efficiency or makes people work more. My answer was that, based on my early experience, money-like stakes seemed to make people take the session more seriously. However, I do not have statistical data yet, so I cannot claim that money improves productivity.
This made me realise that I need to separate perceived motivation from measured effectiveness. A user may feel more pressure because money is involved, but that does not automatically mean they produce better work, focus longer, or feel better about the session.
At this stage, I still think money-like stakes work best among nearby friends. The stake becomes part of the game, and the social relationship makes the accountability feel more real. This is why I prefer the first version of the arena to be used by friend groups rather than strangers. Nudging seems stronger when it happens among people who already know each other, because the social pressure is more meaningful.
However, this is still an assumption that needs testing. Later, I need to compare different stake types.
| Stake type | What it tests |
|---|---|
| No stake | Baseline productivity |
| Points | Low-risk gamification |
| Reputation | Social accountability |
| Money | Financial commitment |
| Privacy / proof visibility | Speculative trust and evidence trade-off |
Preparation
Experiment 2: Trustworthy Focus Integrity
The next experiment will focus on Focus Integrity, not adding more arena features. The research question is:
Which Focus Integrity approach gives the best balance between consistency, fairness, privacy, user trust, and practical implementation?
I will compare timer-only, metadata-only, screen-based, metadata + screen, metadata + screen + AI, camera-presence only, and metadata + screen + camera-presence models. I will replay the same focus sessions through different models, compare model outputs with human labels, and ask users which judgement feels most fair and acceptable.
- 01Which score feels most believable?
- 02Which model feels most fair?
- 03Which evidence feels too invasive?
- 04Would you allow camera presence during a focus session?
- 05Would you prefer proof-of-work or post-session clarification over passive monitoring?
- 06Would you trust this score if money or reputation was involved?
- 07What should happen when the system is uncertain?
- -Identify which models match human judgement better.
- -Identify which models users find acceptable.
- -Find what evidence feels too invasive.
- -Learn how much explanation users need to trust a score.
- -Decide whether a lower-privacy model is good enough for the arena.
Later experiment: stake and social nudge effectiveness
The Week 6 critique also showed me that I need another research strand around money, friends, and nudging. I had assumed that money-like stakes would make users take focus sessions more seriously, especially when used among nearby friends. From my early experience, this seemed true, but I do not yet have statistical data to prove that it improves efficiency or makes users work more.
Do money stakes and friend-based nudging make users work more effectively, or do they mainly increase pressure?
| Condition | Social context | Stake type | What to measure |
|---|---|---|---|
| Solo Pomodoro | Alone | No stake | Baseline completion and perceived focus |
| Friend room | Friends | No money, only visibility | Effect of social accountability |
| Friend room | Friends | Points/reputation | Effect of low-risk gamification |
| Friend room | Friends | Small money stake | Effect of financial commitment |
| Friend room | Friends | Privacy/proof visibility | Effect of speculative evidence-based stakes |
Measures could include completion rate, abandoned sessions, focused minutes, perceived motivation, perceived stress, perceived fairness, willingness to use again, and whether users felt they worked more than usual. This is not the immediate next experiment, but it is an important future research need. Tickers depends on both trustworthy judgement and meaningful motivation. Focus Integrity answers the judgement side. Stake and social nudge testing would answer the motivation side.
Longer-Term Future Direction: Verified Effort as Culture
During the critique, I was also asked about the future direction of the project. At first, I answered that I may explore hardware integration later, but after reflecting on the feedback, I realised that the future direction is larger than hardware alone. Tickers could develop into a broader speculative system about verified effort.
The core idea of Tickers is that focus, effort, and contribution are no longer private or simply trusted. They become visible, measurable, scored, challenged, and sometimes rewarded. This means the project can move in two possible future directions: a Business-to-Business (B2B) version where verified effort becomes part of organisational culture, and a Business-to-Consumer (B2C) version where verified effort becomes part of personal productivity through a physical desk companion.
These directions are not the immediate next step. The priority is still to make the Focus Integrity layer more trustworthy, explainable, and privacy-conscious. However, they help me understand what kind of future culture Tickers is revealing.
B2B Direction: Verified Effort as Social Status
The Business-to-Business (B2B) direction would turn Tickers into an organisational Focus Integrity system for companies, schools, universities, studios, or institutions. In this version, Tickers would not only help individuals focus. It would allow organisations to verify, compare, and reward effort.
For example, a company or school could create verified work rooms where people declare what they are working on, enter a focus session, and have their work behaviour checked through Focus Integrity. The system could use stronger authentication, desktop monitoring, camera presence, screen or app activity, AI judgement, and team dashboards. At the end of a session, the user's work could become a verified effort record.
This could create features such as:
| B2B feature | What it means |
|---|---|
| Verified focus hours | How much work time was accepted as valid |
| Focus Integrity score | How aligned the session was with the declared task |
| Contribution score | How much a person contributed to a team project |
| Trusted contributor badge | A status label based on repeated verified effort |
| Team dashboard | A shared view of effort, progress, and reliability |
| Challenge history | A record of disputed or questioned sessions |
| Access tier | High scores could unlock trusted roles or higher responsibility |
This direction makes the future culture more visible because Focus Integrity becomes a type of social status. People may no longer be recognised only for final outputs. They may also be recognised for how much verified effort they have recorded.
The speculative concern is that this could easily become uncomfortable. A system that begins as productivity support could become workplace or institutional surveillance. If focus scores become connected to rewards, rankings, promotion, trust, or access, then people may start performing focus for the system rather than working naturally. The B2B direction is therefore useful not only as a product idea, but as a warning scenario. It shows how a helpful focus system could become a culture of behavioural judgement.
B2C Hardware Direction: Ticker Cube / Pomo Pet
The Business-to-Consumer (B2C) direction is more personal and domestic. Instead of Tickers becoming an organisational dashboard, it could become a personal focus companion that sits on the user's desk.
This version could take the form of a small matte-black cube, almost like a digital Pomodoro clock mixed with an AI desk pet. I am calling this direction Ticker Cube or Pomo Pet. It would connect to the mobile app, desktop app, Chrome or app lock, Focus Integrity system, and friend-group arena.
The device could include:
| Hardware element | Purpose |
|---|---|
| Cube-shaped matte-black body | Matches the dark and sharp Tickers visual language |
| Front digital display | Shows timer, task, focus state, or a pet-like face |
| Pet-face mode | Makes the system feel more emotional and companion-like |
| Main rotary dial | Lets the user quickly set time, choose tasks, and start sessions |
| Secondary dial or button | Controls mode, privacy setting, volume, or session type |
| RGB light strip | Shows focus state through colour: green for focused, yellow for drift, red for broken, purple for night mode |
| Speaker and microphone | Allows voice input and lightweight conversation |
| Built-in large language model (LLM) | Lets the pet act as a focus coach or task assistant |
| Built-in camera | Supports optional presence-based Focus Integrity |
| Privacy shutter or indicator | Makes camera use visible and controllable |
The Ticker Cube would let users interact with Tickers without always opening the app. A user could turn the dial to set a 30-minute focus session, speak a task aloud, or ask the device to start a Pomodoro. During the session, the cube could show a timer or a simple face. If the desktop app detects uncertainty, the cube could ask a clarifying question such as:
“You have been on Chrome for a while. Is this still part of your task?”
This makes Focus Integrity more contestable. Instead of the system silently judging the user, the user can respond and explain what they are doing.
The B2C direction feels softer than the B2B direction. It is more playful, voluntary, and emotionally engaging. However, it still reveals a speculative risk. Monitoring may become normal not because it is forced by an organisation, but because it feels cute, helpful, and supportive. In this version, verified effort becomes part of self-care, friendship, and daily routine.
This makes the B2C hardware direction useful for the project because it shows another side of the same future culture. B2B shows verified effort as institutional control. B2C shows verified effort becoming normal through companionship.
Why These Directions Matter
These two directions helped me understand that Tickers is not only one app. It is a system that can reveal different versions of a future verified-effort culture.
| Future direction | What it becomes | What it reveals | Main risk |
|---|---|---|---|
| Friend-group Tickers | Arena-based accountability between friends | Effort becomes socially enforced | Pressure, shame, awkward enforcement |
| B2B Tickers | Company or school Focus Integrity dashboard | Effort becomes organisational evidence and status | Surveillance, ranking, misuse |
| B2C Ticker Cube | Personal AI Pomodoro pet on the desk | Monitoring becomes friendly, emotional, and voluntary | Control becomes normal through care |
| Privacy-as-stake mode | Evidence visibility becomes part of the wager | Privacy becomes part of being trusted | Harmful exposure if uncontrolled |
For now, I do not need to choose one final commercial direction. The immediate priority is still to make Focus Integrity more trustworthy, explainable, and privacy-conscious. However, adding these future directions makes the project clearer because it shows what Tickers is really about: a future where effort is no longer simply trusted, but has to be proven through systems.
Arena-based accountability between friends. Effort becomes socially enforced through stakes, proof, and challenge.
Company or school Focus Integrity dashboard. Effort becomes organisational evidence, ranking, and status.
Personal AI Pomodoro pet on the desk. Monitoring becomes friendly, emotional, and voluntary.
Evidence visibility becomes part of the wager. Privacy becomes one of the things people risk in order to be trusted.

A compact desk object that matches the current Tickers visual language.
Shows task, Pomodoro time, focus state, and session progress.
The screen can turn into a simple expressive face, making the system feel like a companion.
Physical controls for setting time, choosing tasks, changing modes, and starting sessions quickly.
Ambient status feedback for focused, drift, warning, completed, or night mode states.
Supports voice task entry, lightweight conversation, focus coaching, and clarification.
Supports presence-based Focus Integrity while making camera use visible and controllable.
Conclusion
Week 6 helped me separate engineering fixes from design research questions. The Pomodoro time record and backend failures were mostly engineering problems, and I fixed most of them so users became more satisfied. But the feedback about Focus Integrity, Chrome lock, money, app deletion, privacy, and friend-group use revealed deeper design questions.
The biggest learning is that Tickers is not just a productivity game. It is a social trust system. The arena can create motivation, especially among friends, but only if the system's record and judgement feel fair.
My next step is to stop expanding the arena and focus on Trustworthy Focus Integrity. I want to compare different evidence models and find the approach that gives the best balance between confidence, fairness, privacy, trust, and ethical acceptability.
I am no longer trying to make one perfect focus score. I am trying to compare different ways of estimating task alignment and decide which one is trustworthy enough for a social arena.
References
- Bassot, B. (2016). The reflective practice guide: An interdisciplinary approach to critical reflection. Routledge.
- Cirillo, F. (2018). The Pomodoro Technique: The acclaimed time-management system that has transformed how we work. Currency.
- Design Research Practice. (2026). DES303 Week 6 2026 [Course handout, University of Auckland].
Note on figures: Figure 1 shows screens captured from the author's Flutter build shipped to TestFlight; Figures 4, 6, and 7 are live screenshots of the author's Focus Integrity score-check dashboard and live overlay; Figure 13 is an AI-assisted concept render of the Ticker Cube produced by the author. All other figures were composed by the author as data tables, diagrams, and reflection frames.