DES303 Week 7: Testing Focus Integrity With Users - Fairness, Privacy, and Trust
Using model comparison as a research instrument
Introduction
In Week 6, user testing and crit feedback revealed that the central problem in Tickers was not simply whether the prototype worked, but whether users could trust the system's judgement. The feedback showed that Focus Integrity could not be treated as a simple score. If it affected arena results, proof, money, reputation, or social pressure, then the score needed to feel explainable, fair, and contestable.
This week I used the model comparison system from Week 6 as a research instrument. The goal was not to prove that the score was correct, but to test whether users understood and trusted the judgement. Instead of adding more arena features, I focused on whether the scoring layer felt fair, explainable, and acceptable to people using it.
By the end of the week, I realised that this assumption was limited. The system could collect data, replay sessions, compare models, and generate structured evidence, but more data did not automatically create better understanding. The experiment showed that Ticker was becoming better at watching the user, but not necessarily better at understanding the task.
The main learning from Week 7 is that Focus Integrity should not start from surveillance data. It has to start from task understanding.
Experience
Why I chose to investigate Focus Integrity
The first crit made the Focus Integrity problem very clear. Even though the prototype was still early, people immediately questioned the accuracy and ethics of the score. This mattered because the whole Tickers system depends on Focus Integrity being believable. If the score is wrong, the arena result becomes unfair. If the score feels hidden or invasive, users may reject the system. If the score is connected to money, reputation, proof, or social pressure, then wrong judgement has real consequences.
So I tried to make my version task-based rather than only activity-based. Instead of asking whether the user was active, Ticker should ask whether the user's observable behaviour matches the task they claimed they were doing.
What is new this week?
Week 7 overlaps with Week 6 because it continues the Focus Integrity problem, but the purpose changed. Week 6 established the trust issue. Week 7 tested whether my first technical answer to that issue was strong enough.
| Week 6 established | Week 7 tested |
|---|---|
| Focus Integrity had a trust problem | Whether tick-based evidence could make the score more trustworthy |
| Users questioned fairness, privacy, and judgement | I built TriScore, collectors, replay comparison, and user correction labels |
| The dashboard began as a response to critique | The dashboard became a research tool for testing the limits of the method |
| The next step was Trustworthy Focus Integrity | The result was that evidence alone was not enough without task context |
Trust in Focus Integrity became the central risk.
Wrong judgement could feel unfair, hidden, or ethically risky.
The next cycle needed to test the method, not add arena features.
Live scoring and replay comparison became the experiment.
Experiment 2: Testing Focus Integrity With Friends
After Week 6, I realised that improving Focus Integrity was not only a technical problem. It was a trust problem. This week I tested the system with a small group of friends to understand whether the score felt fair, which evidence felt acceptable, and where the system misread real study behaviour.
| Test detail | What I did |
|---|---|
| Participants | 4 friends / classmates |
| Session length | 10 minute focus sessions |
| Tasks | coding, essay writing, lecture watching, research browsing |
| Evidence collected | app/window context, input activity, screen change, optional camera presence, model score |
| Human label | I manually labelled each segment as aligned, partial, distracted, or unclear |
| User feedback | short post-test questions about fairness, trust, and privacy |
Evidence of what I actually worked on this week
To make the week more evidential, I treated Focus Integrity as a technical design experiment rather than only a conceptual reflection. I documented the work in four layers: implementation evidence, session evidence, model-comparison evidence, and peer-interpretation evidence. This mattered because the question was not only whether I could describe a scoring system, but whether I could show how the system was built, what data it produced, where it failed, and how that failure changed the direction of the project.
| Workstream | What I built or changed | Evidence to include | What it proves |
|---|---|---|---|
| Live tracker | Built the macOS Focus Integrity overlay with live score and signal rows | Screenshot of tracker running during a real session | The system was not only conceptual |
| Collector pipeline | Added or refined active window, input, camera, screen diff, Chrome, and system state collectors | Annotated architecture and development workspace | Focus Integrity was built from several evidence channels |
| Raw tick logging | Captured repeated session ticks with timestamps, app context, signal values, and verdicts | Raw JSON / log screenshot with labels | The system produced machine-readable behavioural evidence |
| Research replay | Replayed the same session through multiple models | Research Tick dashboard screenshot | I was comparing evidence strategies, not trusting one score |
| Segment labelling | Added aligned / partial / unclear / not aligned correction labels | User correction UI screenshot | The score became contestable |
| Model comparison | Compared model output against human labels | Exploratory model-label agreement graph | The models still struggled with ambiguity |
| Peer interpretation | Asked peers what the score meant and what felt invasive | Small feedback table | The issue was not only accuracy, but trust and explanation |
focus-integrity/
collectors/
ActiveWindowCollector.ts
InputActivityCollector.ts
CameraPresenceCollector.ts
ScreenDiffCollector.ts
ChromeActivityCollector.ts
SystemStateCollector.ts
pipeline/
FeatureExtractor.ts
CertaintyGate.ts
AIJudge.ts
scoring/
TriScoreEngine.ts
SessionStateMachine.ts
research/
ResearchTickReplay.ts
modelComparison.ts[tracker] session started: DES303 Week 7 blog [collector] active_window=Chrome title="DES303 brief" [collector] input=low idle=38s screen_diff=0.04 [ai-judge] verdict=partial confidence=0.61 [triscore] integrity=74 engagement=42 confidence=58 [research] saved tick #034 to replay buffer [replay] models=M0, MA, MS, MB, MAI, CPRES, MPRES
TriScore model — building my first live Focus Integrity architecture
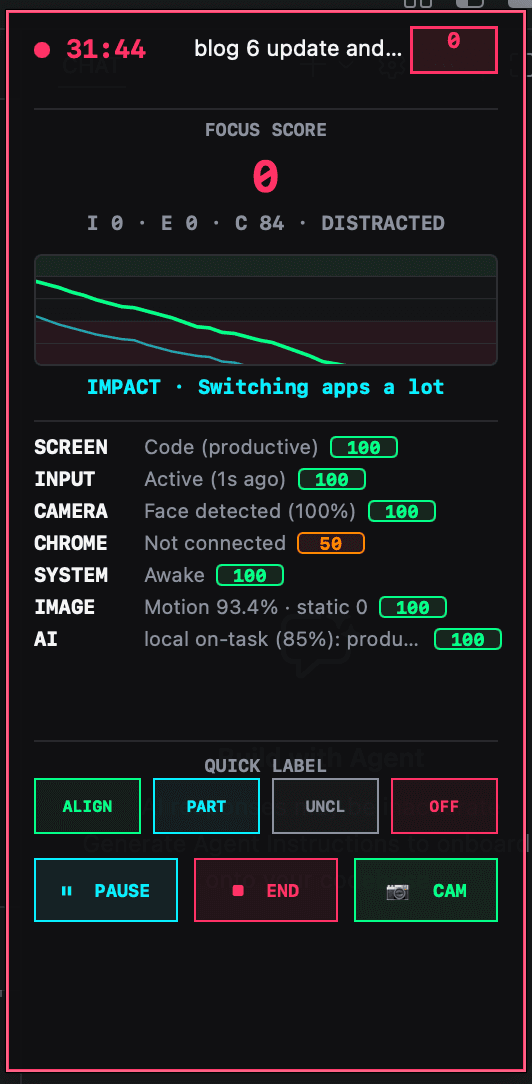
The main research instrument I used this week was the TriScore model. This was my first working version of Focus Integrity as a live system rather than only a product idea. The purpose of the model was to replay and inspect focus sessions in small repeated “ticks”, collect behavioural evidence from the desktop, and test whether the user's current activity still matched the task they had committed to.
This mattered because the Week 6 critique showed that Focus Integrity could not remain as a vague score. If Ticker was going to use the score to affect streaks, arena results, proof, or accountability, then I needed to understand how the judgement was being made. Building the TriScore model was therefore not just technical development. It was a design research experiment into whether focus can be judged fairly through observable signals.
The live system ran in this loop:
Collectors → Feature Extractor → Certainty Gate / AI Judge → TriScore Engine → State Machine → Intervention UI
This structure helped me test what would happen if Ticker judged focus continuously during a session. It also made the weakness of the approach more visible. The system could collect more evidence, but it still struggled to know what the evidence meant.
- -window
- -input
- -camera
- -screen
- -Chrome
- -system
- -rolling buffer
- -app role
- -idle time
- -title match
Clear on-task, clear off-task, or uncertain.
Called only when local evidence is uncertain.
- -Integrity
- -Engagement
- -Confidence
- -focused
- -drift
- -distracted
- -failed
- -warning
- -grace period
- -session fail

The system collected raw signals from the desktop every few seconds through several collectors:
| Collector | What it checked | Why it mattered |
|---|---|---|
| ActiveWindowCollector | Foreground app, bundle ID, window title, active duration | Shows what digital context the user is in |
| InputActivityCollector | Typing, mouse, scroll, idle time | Shows whether the user is actively interacting |
| CameraPresenceCollector | Face presence and gaze stability | Shows whether the user is physically present |
| ScreenDiffCollector | Screen visual change | Shows whether the workspace is changing or static |
| ChromeActivityCollector | Browser / extension violations | Shows possible distracting web use |
| SystemStateCollector | Screen lock, display sleep | Shows whether the session is abandoned or inactive |
This collector table was useful because it made the system's assumptions visible. Each collector translated part of the user's behaviour into data, but none of them could fully explain intention. For example, the ActiveWindowCollector could tell that Chrome was open, but not whether I was researching, watching a lecture, checking documentation, or drifting away from the task. The InputActivityCollector could detect low typing, but low typing might mean reading, planning, thinking, or being distracted. This showed me that adding collectors improved visibility, but did not automatically improve understanding.
| What TriScore proved | What TriScore did not prove |
|---|---|
| A live Focus Integrity tracker can collect desktop evidence during a session | That the evidence correctly understands intention |
| The system can calculate Integrity, Engagement, and Confidence | That those scores feel fair to the user |
| A certainty gate can reduce unnecessary AI calls | That ambiguous work can be judged safely |
| Live intervention is technically possible | That live intervention is always helpful |

{
"tick": 34,
"timestamp": "2026-04-18T14:22:40+12:00",
"declaredTask": "write DES303 Week 7 blog",
"activeApp": "Google Chrome",
"windowTitle": "DES303 Week 7 2026 - Canvas",
"input": { "typing": "low", "idleSeconds": 38 },
"presence": { "camera": "face_not_detected" },
"screen": { "diffRatio": 0.04, "state": "static_reading" },
"aiVerdict": { "label": "drift_risk", "confidence": 0.61 },
"triScore": { "integrity": 74, "engagement": 42, "confidence": 58 },
"humanLabel": "aligned / partial"
}The Feature Extractor then converted this raw telemetry into higher-level features using a rolling buffer of recent ticks — approximately a few minutes of history — and calculated things like app switching rate, dwell time, focus continuity, idle seconds, doom scrolling, typing bursts, face stability, downward glances, screen-diff ratios, and task keyword matching.
How the live TriScore model used AI
I added a certainty gate before the AI Judge so I wouldn't call AI on every tick. If local evidence was clear, the system decided locally. If evidence was unclear, the backend formatted an evidence bundle and Claude returned a structured judgement — on-task yes/no, confidence, and a short reason. That verdict fed back into the TriScore Engine and could move the user through warning, recovery, or failed states.
At this stage the system felt promising — it could respond while the user was working. But it created a serious issue: if the judgement was wrong, the system could interrupt the user unfairly.
One ambiguous test case: when the system could watch but not understand
This ambiguous case became the most important evidence of the week. It showed that the problem was not only model accuracy. The problem was meaning. The same signal could be interpreted in opposite ways depending on the task. This meant the system could be technically detailed and still unfair.
| Observed signal | What the system might assume | What it could actually mean |
|---|---|---|
| Chrome is active | The user is browsing instead of working | The user is researching, reading documentation, or checking references |
| YouTube is open | The user is distracted | The user is watching a lecture, tutorial, or design reference |
| Screen is static | The user has stopped working | The user is reading, thinking, or analysing |
| Low typing activity | The user is idle | The user is planning, reading, or reviewing |
| Camera does not see the face | The user left the session | The user may be writing on paper or looking at another device |
This was the point where the experiment failed productively. The failure was useful because it changed the direction of the project. I no longer wanted to keep adding more surveillance signals. I needed to redesign the system so that it understood the work before judging the behaviour.
| Segment | Evidence | Model read | Human label | Why it was ambiguous |
|---|---|---|---|---|
| 03/10 | Chrome active, low typing, static screen | Drift risk | Aligned / partial | I was reading course material for the blog |
| 04/10 | YouTube open, no typing | Distracted | Partial | It could be tutorial/reference, but the system lacked task context |
| 05/10 | Camera absent | Off-task | Unclear | I may have been writing notes on paper |
Research Tick / Replay model — the investigation system
I therefore created a separate Research Tick / Replay system. This was not designed to control the user live. It was designed to help me investigate which data was truly meaningful.
Because Week 6 had already introduced the score-check dashboard, I used Week 7 to push the dashboard further as a research tool. The main change was not simply adding more models, but using the replay system to ask why each model still failed in ambiguous task situations.
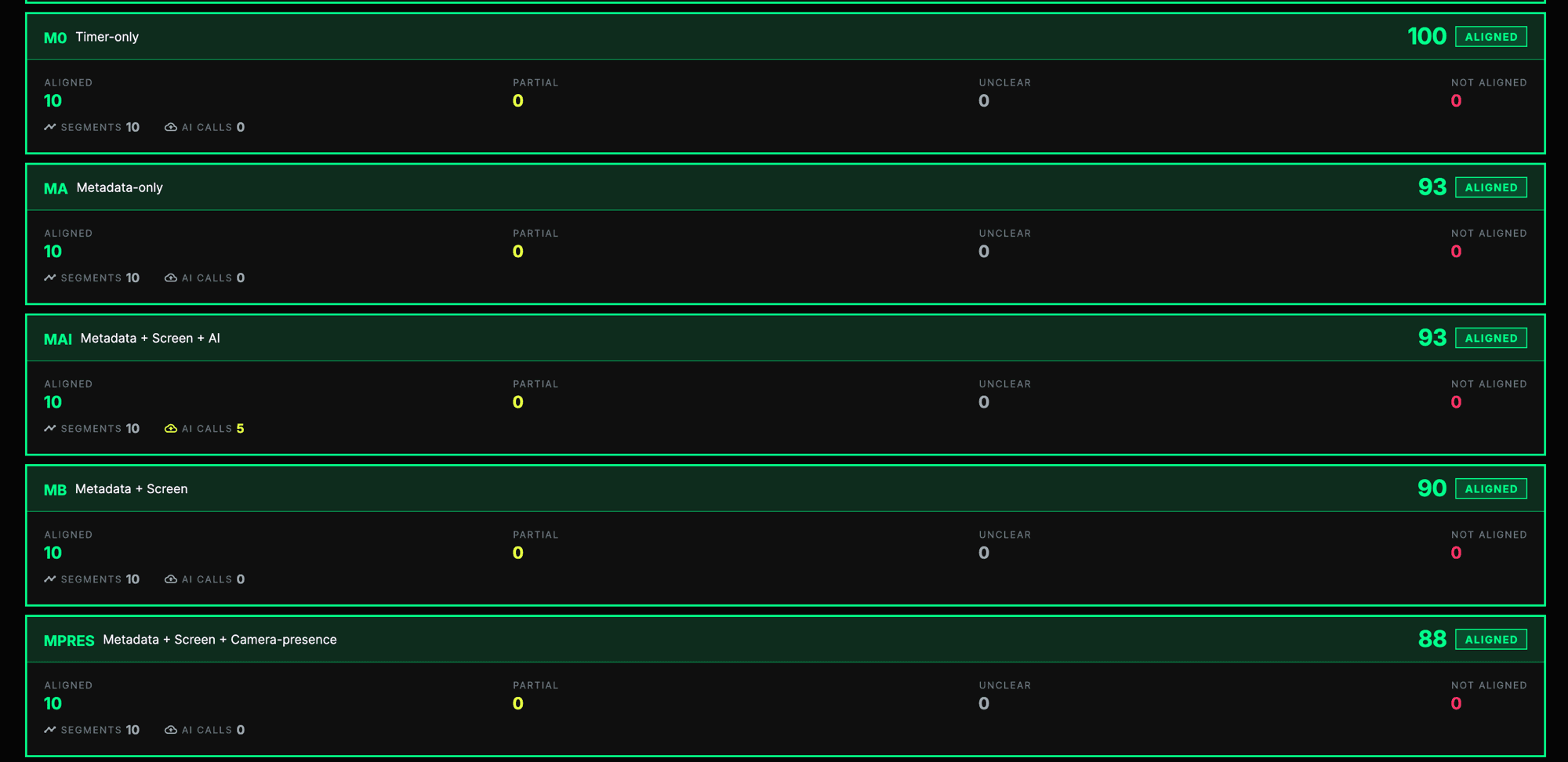
| Model | Evidence used | Why I tested it | Week 7 learning |
|---|---|---|---|
| M0 | Duration only | Baseline | Too private to be meaningful |
| MA | App, input, dwell time | Privacy-preserving telemetry | Useful but weak for intention |
| MS | Screen heuristics | Task evidence | Stronger but privacy-heavy |
| MAI | Metadata + screen + AI | AI judgement | Helpful but can sound too certain |
| CPRES | Camera presence | Physical presence | Presence is not focus |
| MTRAJ | Sequence over time | Previous/next segment context | Better than single ticks, still not task-aware |
| MLLM | Local LLM judge | Private AI judgement | Promising, but only if task context is rich |
This changed Focus Integrity from a single-score problem into a comparison problem. I was no longer asking whether one model was “right”. I was asking which evidence types improved judgement, which were too invasive, and which were too expensive or unreliable to use.
Checks the user while the session is active.
Warnings can affect the experience immediately.
Works from the newest behavioural evidence.
Integrity, engagement, and confidence.
A bad reading can interrupt the user unfairly.
The product outcome is live support.
Uses saved data instead of controlling the user.
Several evidence strategies can be tested safely.
The same session can be replayed repeatedly.
The result is comparison, not a live judgement.
Mistakes affect research, not the user session.
The design outcome is a better evidence strategy.


How I tried to correct the data
My idea was that users could correct segments when the system was wrong — labelling them as aligned, partial, unclear, or not aligned. These corrections would become ground truth so the system could learn each user's focus pattern over time. This connects to data labelling in machine learning, where models need labelled examples to interpret raw data correctly.
- 01User starts focus session
- 02Ticker records 10-second ticks
- 03Ticks are grouped into segments
- 04Each model predicts aligned, partial, unclear, or not aligned
- 05User corrects wrong labels
- 06Corrections become ground truth
- 07System learns user behaviour over time
Friend testing: fairness, privacy, and trust
After building the Research Tick replay system and user correction overlay, I ran a small formative test with four friends / classmates. This was not intended to prove that the model was accurate. The aim was to test whether people could understand what the Focus Integrity score was trying to communicate, which evidence signals felt acceptable, and where the judgement felt unfair or invasive.
I showed users the live tracker, replay dashboard, and ambiguous segments from short focus sessions. I then asked them to explain what they thought the score meant, which evidence they trusted, which evidence felt too invasive, and what they would want to happen if the system judged them incorrectly. This was a small qualitative check. NN/g argues that small formative usability tests are useful for finding design problems and supporting iteration, while larger samples are needed for quantitative claims (Nielsen, 2000, 2012).


| Question | Scale |
|---|---|
| Did the score feel fair? | 1 to 5 |
| Did the system explain itself clearly? | 1 to 5 |
| Did any evidence feel too invasive? | 1 to 5 |
| Would you trust this score if money/reputation was involved? | 1 to 5 |
| What should happen when the system is uncertain? | Short answer |
| Participant | Task | System result | Human label | Fairness rating | Privacy comfort | Key comment |
|---|---|---|---|---|---|---|
| P1 | Coding | Mostly aligned | Aligned | 4/5 | 3/5 | The score felt okay, but I wanted to know why it dropped. |
| P2 | Essay writing | Partial | Aligned/unclear | 3/5 | 4/5 | Reading looks inactive, so the system needs a pause/reading mode. |
| P3 | Lecture watching | Distracted | Aligned | 2/5 | 3/5 | YouTube can be work depending on the task. |
| P4 | Research browsing | Partial | Partial | 4/5 | 2/5 | Screen evidence feels strong, but I would not want raw screenshots shared. |
| Week 6 model assumption | Week 7 user response | Next design change |
|---|---|---|
| More evidence will make the score feel fairer | Users accepted monitoring only when the system could explain why a score changed | Show score reasons beside the number |
| Low typing or low input means drift | Essay writing and reading can look inactive even when the user is aligned | Add a pause / reading mode before warning the user |
| YouTube or browser use is usually distraction | Lecture watching and research browsing can be legitimate work | Compare evidence against the declared task, not against generic app categories |
| Camera presence makes the score stronger | Presence felt sensitive and did not always prove focus | Make camera evidence optional and clearly separate from core scoring |
| The model can make a final judgement | Users wanted correction, appeal, and an uncertain state | Make Focus Integrity explainable, contestable, and privacy-aware |
| Question | User response pattern | What I learnt |
|---|---|---|
| What do you think the score means? | Some users read it as an attention score rather than a task-alignment estimate. | The system needs clearer language. Focus Integrity should not sound like mind-reading. |
| Which evidence feels reasonable? | Active app, window title, and task-related screen context felt easiest to understand. | Users are more willing to accept evidence when it clearly connects to the declared task. |
| Which evidence feels invasive? | Camera presence felt more sensitive than app or window data. | Presence checking needs stronger consent, explanation, or an alternative. |
| What should happen if the score is wrong? | Users wanted correction, appeal, or clarification. | Focus Integrity needs to be contestable, not final. |
| Would you trust this in an arena? | Users said trust depends on seeing the reason behind the score. | Explanation matters more than the number alone. |
The user test confirmed that the problem was not only technical accuracy. Even if the model produced a score, users still needed to understand why the score happened and what they could do when it was wrong. This supported my Week 7 finding that tick-based evidence is not enough by itself. The next version needs task context, uncertainty, and clarification before judgement. Combining implementation evidence, replay evidence, and peer interpretation also helped me triangulate the finding instead of relying on one evidence source (Whitenton, 2021).
Reflection on Action
My main learning
The biggest learning this week was that my Focus Integrity research method was too focused on accuracy and not enough on meaning. At the start of the week, I thought the main problem was that the score needed more evidence. My logic was:
more ticks → more collectors → more model comparison → more user correction → more reliable Focus Integrity
After building the TriScore model and the Research Tick / Replay system, I realised that this assumption was limited. The system could become more technically detailed, but that did not mean it became more fair or more useful.
The issue was not only whether the model had enough data. The issue was whether the model understood what the user was trying to do. Chrome could be distraction or research. A static screen could be inactivity or deep reading. Low typing could be avoidance or thinking. YouTube could be entertainment or learning. Without task context, the same behaviour could produce the wrong judgement.
This changed my understanding of Focus Integrity. I no longer saw it as a simple detection problem. I began to see it as a task-alignment problem. The system should not ask only, “Is the user active?” or “Does this behaviour look focused?” It should ask, “Does this behaviour make sense for the task the user committed to?”
This shift was important because it changed the direction of the project. Before Week 7, I was trying to make Ticker a better focus detector. After Week 7, I started to question whether detection was the right starting point at all. The experiment showed that surveillance can create confidence without creating understanding. A system may look more intelligent because it collects more data, but if it does not understand the task, it can still make unfair or unhelpful judgements.
| Version A: Tick detector | Version B: Task-aware verifier |
|---|---|
| Starts with behavioural data | Starts with task context |
| Watches app, input, camera, screen | Understands expected work pattern first |
| Warns when signals look suspicious | Asks clarification when evidence is ambiguous |
| Treats labels as correction after judgement | Uses task contract before judgement |
| Risk: surveillance without meaning | Goal: verification with explanation |
Why this failed as a design direction
Ticker was not made only so that AI could check whether a user is focused. The larger purpose was to help the user focus further. The tick-based method did not do that well. It mainly monitored the user and reacted after it suspected drift. It did not properly structure the work before the session. It did not understand why the user chose a task, or help them decide what to do next.
My broader project tension is about AI increasing efficiency while surveillance becomes normalised. But this version mostly increased surveillance without enough improvement in efficiency. The more believable future is a system that becomes useful enough that people accept being watched.
How can I make the score more accurate?
What does the system need to understand before it has the right to judge?
My positionality as a designer
This week also showed me something about my own design pattern. I am comfortable building systems — infrastructure, data models, backend logic, scoring engines, full product flows. This is a strength. It is also a weakness because I sometimes treat design uncertainty as an engineering problem. I responded to the trust problem by building more architecture: more collectors, more models, more replay systems. The deeper I went into tick-based detection, the more I realised the issue was not missing logic. It was missing context.
This connects back to my wider design pattern. Because I am comfortable building full systems, I often respond to uncertainty by adding infrastructure. In Week 7, that strength became a blind spot. I made the system more complex before fully questioning whether behavioural detection was the right starting point.
Theory
Why behaviour data alone was not enough
The Week 7 experiment needed research grounding because Focus Integrity sits between productivity tracking, artificial intelligence, and surveillance. At first, I treated Focus Integrity as a detection problem: if the system collected enough behavioural signals, it could decide whether the user was focused or distracted. The experiment showed that this was too simple.
Context-aware computing
Dey (2001) defines context as information that helps characterise the situation of a person, place, or object. For Ticker, this means active app, window title, typing activity, and screen movement are not meaningful by themselves. They only become meaningful when connected to the user's actual task.
Dourish (2004) also reframes context as something produced through activity and interpretation, not a fixed background variable. This directly matched my ambiguous test cases. Chrome, YouTube, a static screen, or low typing cannot automatically be classified as distraction because the same signal can mean research, learning, planning, reading, or avoidance depending on the task.
Human-AI interaction
Human-AI interaction research helped me question how confident Focus Integrity should appear to be. If Ticker gives a score without showing uncertainty, the interface may feel more objective than it actually is. Amershi et al. (2019) argue that AI systems should make capabilities and limits clear, support correction, and adapt cautiously. This connects directly to my correction-label idea and to the next step: clarification questions when the evidence is ambiguous.
Surveillance and workplace monitoring
The surveillance literature made the project ethically more serious. Ajunwa et al. (2017) show how worker monitoring can become expansive when productivity behaviour is turned into judgement. Urquhart et al. (2022) also show that AI-enabled workplace surveillance raises questions about privacy, agency, and trust. This matters for Ticker because Focus Integrity could easily become a system that watches more simply because more signals are technically available.
| Theory | What it changed in my design |
|---|---|
| Context is interpreted, not simply captured | Ticker needs task context before judging behaviour |
| AI systems should show limits and support correction | Focus Integrity needs user correction and clarification |
| Monitoring can affect privacy, agency, and trust | Ticker should avoid adding signals just because it can |
Why this is not just a machine learning problem
Focus Integrity cannot be treated as a simple classification problem because the labels are not stable. “Focused” or “not focused” depends on task context, intention, tool choice, working style, and sometimes the user's internal state. The same behaviour can mean different things in different contexts, so the design problem is not only how to train a better model. It is how to define, explain, and contest the judgement before the system acts on it.
Preparation
Week 8 pivot: from detector to task-aware AI senior
Week 8 will not be another scoring experiment. It will be a framing and communication week. I need to prepare Crit 2 by showing the pivot clearly: Ticker is moving from a focus detector to a task-aware AI senior. The next prototype should show how the AI understands the task before the session starts, creates a focus contract, and asks clarification questions when the evidence is ambiguous.
Can Focus Integrity become more meaningful if Ticker understands the task before the session starts, instead of only judging behavioural ticks during the session?
Week 8 preparation plan
| Week 8 task | Why it matters |
|---|---|
| Refine reverse brief | Clarify that Ticker is about verified effort, not only productivity |
| Prepare Crit 2 slide | Communicate the pivot from detector to AI senior |
| Prototype task import / focus contract | Show how task context enters the system |
| Add clarification flow | Show how the system handles uncertainty without unfair warning |
| Test with peers | Ask whether this feels more helpful, less invasive, or still controlling |
Conclusion
Week 7 showed me that Focus Integrity cannot be designed as a simple accuracy problem. Users were willing to accept some monitoring when it helped them stay accountable, but they became less comfortable when the system could not explain why a score dropped. The most important finding was that trust depends on explanation, not only detection.
A lower-evidence model may be more acceptable if it is transparent, while a stronger evidence model may become too invasive if users cannot control what is captured. This shifts my next step from “make the model more powerful” to “make the judgement more explainable, contestable, and privacy-aware.”
Trust depends on explanation, not only detection.
References
- Ajunwa, I., Crawford, K., & Schultz, J. M. (2017). Limitless worker surveillance. California Law Review, 105(3), 735–776. https://doi.org/10.15779/Z38BR8MF94
- Amershi, S., Weld, D., Vorvoreanu, M., Fourney, A., Nushi, B., Collisson, P., Suh, J., Iqbal, S., Bennett, P. N., Inkpen, K., Teevan, J., Kikin-Gil, R., & Horvitz, E. (2019). Guidelines for human-AI interaction. Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 1–13. https://doi.org/10.1145/3290605.3300233
- Design Research Practice. (2026). DES303 Week 7 2026 [Course handout, University of Auckland].
- Dey, A. K. (2001). Understanding and using context. Personal and Ubiquitous Computing, 5(1), 4–7. https://doi.org/10.1007/s007790170019
- Dourish, P. (2004). What we talk about when we talk about context. Personal and Ubiquitous Computing, 8(1), 19–30. https://doi.org/10.1007/s00779-003-0253-8
- Nielsen, J. (2000, March 18). Why you only need to test with 5 users. Nielsen Norman Group. https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users/
- Nielsen, J. (2012, June 3). How many test users in a usability study?Nielsen Norman Group. https://www.nngroup.com/articles/how-many-test-users/
- Urquhart, L., Laffer, A., & Miranda, D. (2022). Working with affective computing: Exploring UK public perceptions of AI enabled workplace surveillance. In Proceedings of Ethicomp 2022, University of Turku (pp. 164–177). https://doi.org/10.48550/arXiv.2205.08264
- Whitenton, K. (2021, February 21). Triangulation: Get better research results by using multiple UX methods. Nielsen Norman Group. https://www.nngroup.com/articles/triangulation-better-research-results-using-multiple-ux-methods/
Note on figures: Custom diagrams, reconstructed evidence views, and rating charts are based on the author's Week 7 development logs, replay tests, labelled segments, and peer testing notes. Figures 4, 7, and 10 are screenshots from the author's Ticker / Focus Integrity prototypes. Experiment 2 participant photographs are author-captured test documentation with face areas blurred before publication. All diagrams and prototype screenshots were built and rendered by the author, 2026.